
CapAI是一个多模态AI项目,旨在开发一个“自由”的模型系列。
接下来将训练CapAI对话模型第二代,计划使用Baichuan2-13B-Base作为基座进行微调。
本人高二学生,只有一张P40显卡。为了实现更好的效果,在腾讯云租一台带V100的服务器用于本次训练。这货还是蛮吃显存的。
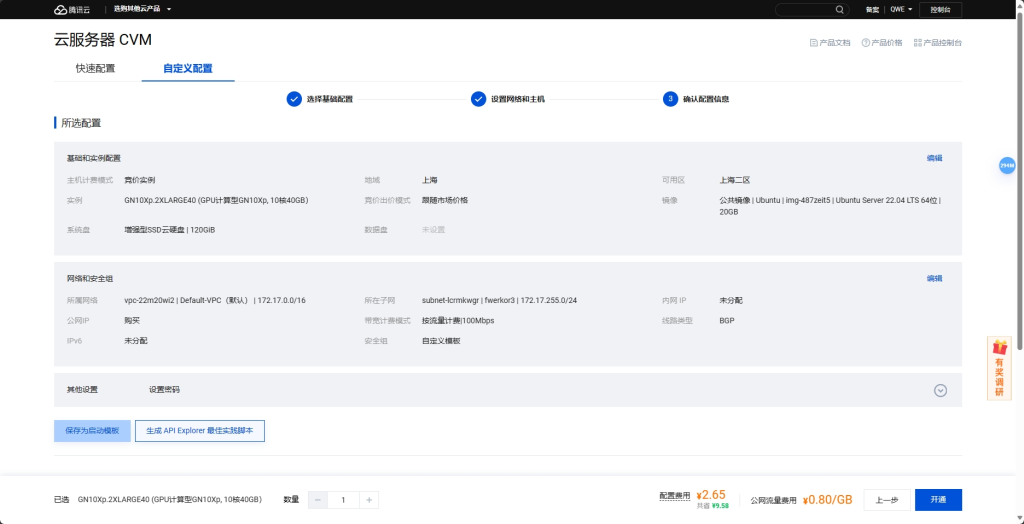
腾讯云竞价实例还是比较便宜的……吧……
宽带也是钱啊!幸好我还有两个上海的轻量,有流量包,可以从内网与运算服务器收发数据。
用LLaMA Factory来训练,自带一些整理好的参数集。
自动安装驱动是一个漫长的过程……每一秒都是钱啊!为什么就不能把驱动集成在镜像里呢。
Hello, This script will download and install the GPU driver, CUDA, CUDNN library automatically, you can not suspend or stop it until completed.
1. The whole process will take about 15 to 25 minutes. During this time, please do not operate the GPU or install any GPU related software.
Driver install finished: NVIDIA-Linux-x86_64-535.161.07.run, the remaining installation needs about 14-19 minutes.
Downloading cuda: cuda_12.2.2_535.104.05_linux.run, it will take about 3 minutes. the remaining installation needs about 13-18 minutes.
[####################################################################################################] 100% /
Installing cuda: cuda_12.2.2_535.104.05_linux.run, it will take about 5 minutes. the remaining installation needs about 12-16 minutes.
[####################################################################################################] 100% /
Downloading cudnn: cudnn-linux-x86_64-8.9.4.25_cuda12-archive.tar.xz, it will take about 2 minutes. the remaining installation needs about 4-7 minutes.
[####################################################################################################] 100% /
Installing cudnn: cudnn-linux-x86_64-8.9.4.25_cuda12-archive.tar.xz, it will take about 2 minutes. the remaining installation needs about 2-3 minutes.
[####################################################################################################] 100% /
All install OK! Enjoy it!这服务器就只是用来这一次训练,完事就销毁,所以不考虑环境隔离的问题了,直接安装。
apt install python3
pip3 install llmtuner==0.5.1
git clone https://github.fwerkor.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory开个守护进程,防手滑。
apt install screen
screen -S capai上传参数集、上传基座模型,训练启动!
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--do_train True \
--model_name_or_path model/Baichuan2-13B-Base \
--finetuning_type lora \
--template default \
--dataset_dir data \
--dataset identity,alpaca_gpt4_en,alpaca_gpt4_zh,oaast_sft,oaast_sft_zh,glaive_toolcall,belle_dialog,belle_math,belle_multiturn,ultra_chat,mathinstruct,firefly,alpaca-gpt4_de \
--cutoff_len 1024 \
--learning_rate 0.0001 \
--num_train_epochs 1.0 \
--max_samples 8000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--lora_rank 64 \
--lora_dropout 0.1 \
--lora_target all \
--output_dir saves/Baichuan2-13B-Base/lora/train_2024-04-13-18-39-54 \
--fp16 True \
--plot_loss True训练参数说明如下(摘自微调百川Baichuan-13B保姆式教程,手把手教你训练百亿大模型 – 知乎 (zhihu.com)):
- output_dir:训练输出目录,存储checkpoint、tokenizer、tensorboard等
- model_name_or_path:预训练模型的本地目录,或者在huggingface上的模型名称。
- train_file:训练数据集路径。可以使用data/dummy_data.jsonl进行debug,或者指定为本地的训练文件。
- num_train_epochs:训练的轮次。如果数据量足够大,一般建议只训一个epoch。
- per_device_train_batch_size:每张显卡的batch size。
- gradient_accumulation_steps:梯度累计步数。global batch=num_gpus * per_device_train_batch_size * gradient_accumulation_steps。
- gradient_checkpointing:如果显存捉襟见肘,可以开启。以时间换空间,模型不缓存激活状态,会进行两次forward计算,以节省显存,我们默认开启。
- learning_rate:学习率。全量参数微调的时候,建议小一些,1e-5或5e-6。qlora训练时,根据模型大小的不同,建议设置为2e-4或1e-4。
- max_seq_length:训练时的最大长度。按照自己的设备进行设置,越长需要占用越多显存。
- logging_steps:每隔多少步打印一次train loss,结果会打印到日志中,也会保存在tensorboard中。
- save_steps:每隔多少步保存一次模型。
- save_total_limit:output_dir目录中最多保存多少个checkpoint,超出则会将最旧的删除。
- lr_scheduler_type:学习率变化策略。
- warmup_steps:warm up步数。学习率经过多少步,增长到指定的数值。
- optim:优化器。如果是全量参数微调,建议使用adamw_hf。如果是qlora微调,建议使用paged_adamw_32bit。
- seed:随机种子,用于复现实验结果。
- fp16:使用使用fp16混合精度。V100建议开启。
- bf16:使用使用fp16混合精度。A100建议开启。
- lora_rank:qlora矩阵的秩。一般设置为8、16、32、64等,在qlora论文中作者设为64。越大则参与训练的参数量越大,一般来说效果会更好,但需要更多显存,。
- lora_alpha: qlora中的缩放参数。一般设为16、32即可。
- lora_dropout: lora权重的dropout rate。
小插曲:脑子短路,在本地电脑上执行了命令,还等了半天。
我用实践证明了腾讯云上海机房的环境温度是32摄氏度。
这就成功了?当然没有!
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 592.00 MiB. GPU 0 has a total capacity of 31.74 GiB of which 182.38 MiB is free. Including non-PyTorch memory, this process has 31.56 GiB memory in use. Of the allocated memory 30.99 GiB is allocated by PyTorch, and 205.13 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)32GB显存还差一点?懒得搞了!既然要用QLoRA,我的P40也可以担当此重任。
中途还去吃了顿晚饭,浪费两个小时。
P40是时候登场了。其实上周我就用P40进行了一次训练,主要参考了单卡 3 小时训练专属大模型 Agent:基于 LLaMA Factory 实战 – 知乎 (zhihu.com),要训练两轮,七八天时间。我装机的时候机箱买小了,P40又是被动散热,要另装风扇,大风扇装不下,只能装了个万转小风扇,声音超大。为了不让它在周末影响我,当时就先训练了一轮,大概用了三天时间。已经可以实现基本对话了,效果还可以。
当时我从淘宝买P40的时候价格是820元,才过了两个月不到的时间,价格都已经涨到一千三左右了。

廉颇老矣,尚能饭否?
能!